マルチエージェントのデータ共有、どう実現する?セキュリティと効率を両立する実践アーキテクチャ
複数のAIエージェントが連携して動作する「マルチエージェントシステム」。その可能性に多くの開発者が魅了されています。しかし、コンセプト実証(PoC)から本格的な開発へ進むにつれて、多くのチームが共通の壁に突き当たります。それが「エージェント間のデータ共有」という複雑な課題です。
「すべての情報を全エージェントで共有すれば簡単だが、セキュリティが心配だ…」
「個別に情報を渡すようにしたら、コードがスパゲッティのように複雑化してしまった…」
「大規模なデータを扱うと、LLMのコンテキストウィンドウがすぐに溢れてしまい、性能もコストも悪化する…」
このような悩みを抱えていませんか? データ共有の設計は、マルチエージェントシステムの性能、セキュリティ、そして開発効率そのものを左右する、まさに心臓部と言える要素です。この設計を誤ると、後々の手戻りや運用時のトラブルに繋がりかねません。
この記事では、マルチエージェントシステムにおけるデータ共有の課題を整理し、セキュリティと効率を両立させるための具体的なアーキテクチャと実践的な戦略を徹底的に解説します。この記事を最後まで読めば、あなたのプロジェクトに最適なデータ共有の方法を見つけ、より堅牢でスケーラブルなAIシステムを構築するための確かな知識が身につくはずです。
なぜマルチエージェントのデータ共有は難しいのか?3つの落とし穴
一見シンプルに見えるデータ共有ですが、マルチエージェントシステム特有の性質から、多くの開発者が予期せぬ問題に直面します。まずは、よくある3つの落とし穴について理解を深めましょう。
H3: セキュリティの罠:機密情報の漏洩リスク
最も深刻な問題がセキュリティです。例えば、顧客情報を扱うシステムを考えてみましょう。顧客データベースにアクセスするエージェント、分析を行うエージェント、レポートを生成するエージェントがいるとします。もし、すべてのエージェントがデータベース全体にアクセスできる設計になっていたらどうなるでしょうか。
レポート生成エージェントは、本来必要のない個人情報にまでアクセスできてしまいます。万が一このエージェントに脆弱性があれば、そこから大規模な情報漏洩に繋がる可能性があります。これは「最小権限の原則」に反する危険な設計です。必要なエージェントに、必要な情報だけを、必要な期間だけ渡す。この原則をいかにシステムとして担保するかが最初の課題です。
H3: 効率性の罠:冗長なデータ転送とコンテキストウィンドウの圧迫
次に問題となるのが効率性です。特に大規模言語モデル(LLM)をベースにしたエージェントでは、コンテキストウィンドウの管理が性能とコストに直結します。あるタスクを複数のエージェントで分担する場合を想像してください。
エージェントAが処理した結果(数万トークンにも及ぶ中間生成物を含む)を、そのままエージェントBに渡していませんか? エージェントBが本当に必要なのは、その中のごく一部の要約された情報だけかもしれません。このような冗長なデータ転送は、LLMのAPIコストを無駄に増加させるだけでなく、コンテキストウィンドウを不必要な情報で満たし、エージェントの処理精度を低下させる原因にもなります。エージェント間の通信をいかに最適化し、コスト効率を高めるかが問われます。
H3: 整合性の罠:データの一貫性が崩れる「サイロ化」問題
セキュリティを意識するあまり、各エージェントが必要なデータを個別に保持する「サイロ化」に陥るケースも少なくありません。各エージェントが独自のデータコピーを持つと、あるエージェントがデータを更新しても、他のエージェントが古い情報を参照し続けてしまう可能性があります。
「顧客の問い合わせ対応エージェントが住所変更を受け付けたのに、配送手配エージェントが古い住所に荷物を送ってしまった」
このようなデータの不整合は、システムの信頼性を著しく損ないます。システム全体で唯一の信頼できる情報源(Single Source of Truth)をどのように維持し、エージェント間でデータの一貫性を保つか、というアーキテクチャレベルの設計が不可欠です。
データ共有の課題を解決する3つの基本アーキテクチャ
前述した課題を解決するために、先人たちが築き上げてきた代表的な3つのアーキテクチャパターンが存在します。それぞれの特徴を理解し、システムの要件に合わせて選択・組み合わせることが重要です。
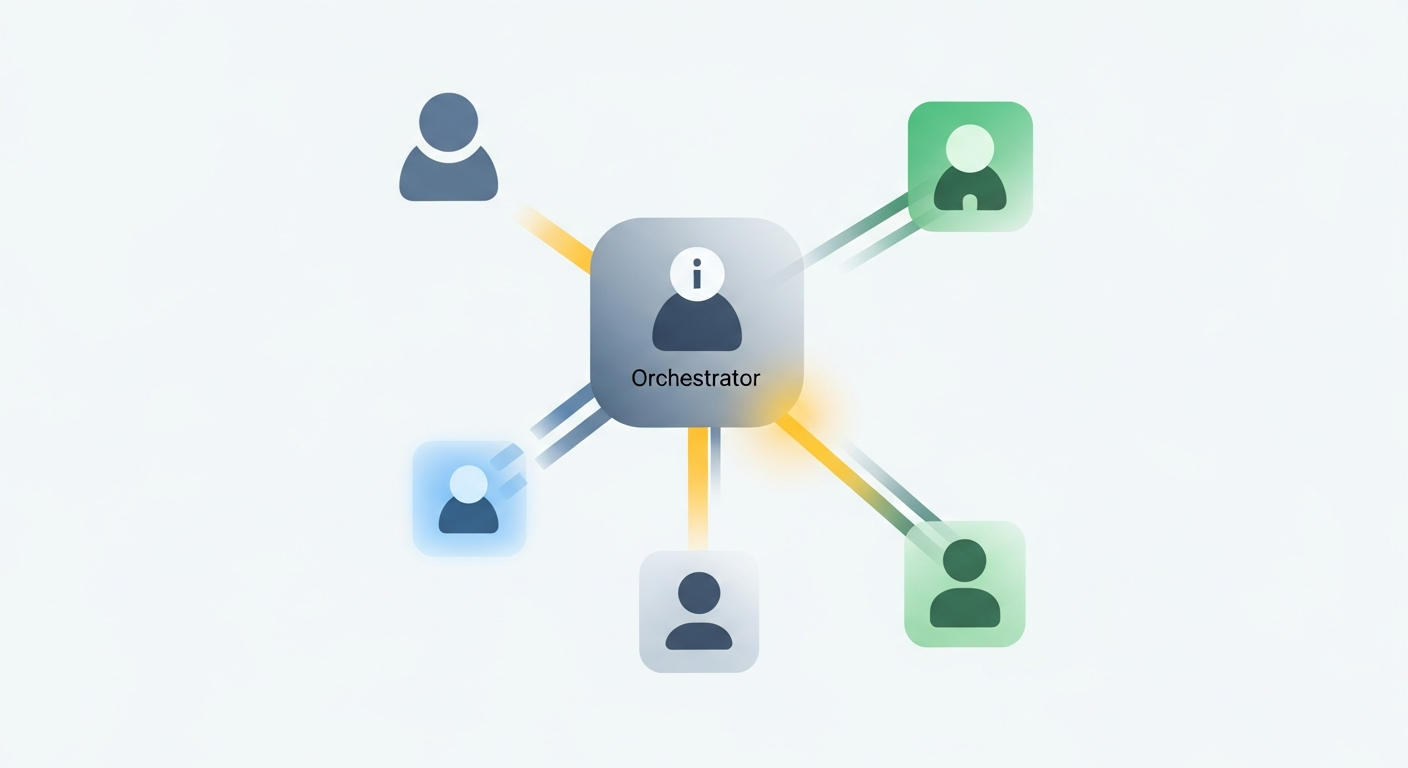
H3: Orchestratorパターン:中央管理による安全な情報仲介
最も一般的で強力なパターンの一つが、全体を統括する「Orchestrator(指揮者)」エージェントを置く方法です。個々のエージェント(ワーカーエージェント)は直接通信せず、すべての情報連携はOrchestratorを介して行われます。
- 仕組み: Orchestratorがタスク全体を管理し、各ワーカーエージェントの役割に応じて必要なデータだけを切り出して渡します。ワーカーエージェントからの結果も一旦Orchestratorが受け取り、次のワーカーエージェントに必要な形に加工して渡します。
- メリット:
- 高いセキュリティ: データフローが一元管理されるため、誰がどの情報にアクセスしたかの追跡が容易。役割ベースのアクセス制御も実装しやすい。
- シンプルな連携: ワーカーエージェントはOrchestratorとのやり取りだけを考えればよく、他のエージェントの存在を意識する必要がないため、コンポーネントの独立性が高まります。
- 手戻りの削減: Orchestratorパターンを用いることで、複雑なAIシステムのコンポーネント間の連携を効率化し、統合テストでの手戻りを削減します。
- デメリット: Orchestratorに処理が集中するため、システム全体のボトルネックになる可能性があります。
このパターンは、複雑なワークフローを持ち、セキュリティ要件が厳しいシステムに適しています。Orchestratorパターンの詳細な設計・実装ガイドも併せてご覧ください。
H3: 共有データストアパターン:外部データベースを活用した非同期連携
すべてのエージェントがアクセスできる共通のデータベースやストレージ(共有データストア)を介して情報をやり取りする方法です。揮発的な情報にはRedisのようなインメモリデータベース、永続的な情報には通常のRDBやNoSQL、ベクトルデータにはVector DBなどが利用されます。
- 仕組み: エージェントAが処理結果を共有データストアに書き込みます。エージェントBは、自身のタスクに必要な情報をデータストアから読み出して処理を続けます。エージェント同士は直接通信しません。
- メリット:
- 非同期処理: エージェント同士が互いの処理完了を待つ必要がなく、疎結合なシステムを構築できます。
- データの永続化: 処理の途中でシステムが停止しても、データストアに状態が保存されているため、途中から処理を再開できます。エラーリカバリ戦略と相性が良いです。
- スケーラビリティ: 同じ役割のエージェントを複数起動して、並列処理させやすい構造です。
- デメリット: データストアへのアクセスが集中すると性能が劣化する可能性があります。また、誰がいつデータを更新したかを管理する排他制御の仕組みが別途必要になります。
H3: Pub/Sub(出版/購読)パターン:特定イベントに基づく柔軟な情報伝達
Pub/Sub(Publish/Subscribe)パターンは、特定の「トピック(イベントの種類)」に対して、情報を送る側(Publisher)と受け取る側(Subscriber)が分離されたメッセージングモデルです。
- 仕組み: Publisher(例:新規顧客登録を検知するエージェント)が「新規顧客登録」というトピックにメッセージを発行します。このトピックを購読しているSubscriber(例:ウェルカムメール送信エージェント、分析データベース登録エージェント)だけが、そのメッセージを受け取って各自の処理を実行します。
- メリット:
- 高い拡張性: 新しい機能を追加したい場合、既存のシステムに影響を与えることなく、新しいSubscriberエージェントを追加するだけで済みます。
- 柔軟性: Publisherは誰がメッセージを受け取るかを意識する必要がなく、システム全体の柔軟性が向上します。
- デメリット: メッセージが確実に届いたかどうかの管理や、処理の順序制御が複雑になる場合があります。
これらのアーキテクチャは排他的なものではありません。大規模なシステムでは、全体をOrchestratorパターンで統括しつつ、特定の非同期処理には共有データストアを、外部イベントとの連携にはPub/Subパターンを、というように複数のパターンを組み合わせて利用するのが一般的です。
【実装レベルで解説】セキュリティと効率を両立する高度なデータ共有戦略
基本的なアーキテクチャを理解した上で、さらに一歩進んだデータ共有戦略を見ていきましょう。これらの戦略を組み合わせることで、より堅牢で洗練されたシステムを構築できます。
H3: 役割ベースのアクセス制御(RBAC)の実装
これは、Orchestratorパターンと非常に相性の良い戦略です。「最小権限の原則」を具体的に実装する方法と言えます。各エージェントに「ロール(役割)」を割り当て、そのロールごとにアクセス可能なデータの種類や実行可能な操作を厳密に定義します。
例えば、「顧客情報分析ロール」を持つエージェントは、個人を特定できないように匿名化された購買履歴データにのみ読み取りアクセスを許可し、「顧客サポートロール」を持つエージェントは、担当する顧客の連絡先情報にのみ読み書きアクセスを許可する、といった制御を行います。これにより、万が一特定のエージェントが不正利用されても、被害を最小限に食い止めることができます。この考え方は、AIの責任範囲を明確化しセキュリティを強化する設計術でも詳しく解説しています。
H3: データ抽象化レイヤーの導入
生データをエージェント間で直接やり取りするのではなく、間に「データ抽象化レイヤー」を設けるアプローチです。このレイヤーは、生データを受け取り、各エージェントの役割に応じて必要な情報だけを抽出・加工した「ビュー」を生成して提供します。
- セキュリティ向上: 生データへの直接アクセスを防ぎ、マスキングや匿名化といった処理をこのレイヤーで一元的に行えます。
- コンテキスト効率化: LLMエージェントに対して、タスクに無関係な情報を取り除いた、必要最小限のコンテキストを提供できます。これにより、複雑なタスクに必要な情報をAIエージェントに十分に与え、性能向上を図ります。
- 保守性の向上: 将来、データソースの形式が変更されても、この抽象化レイヤーを修正するだけで、各エージェントのコードを変更する必要がなくなります。
H3: 差分データ共有による通信コストの最適化
特に定常的に稼働するシステムにおいて、エージェント間で同じようなデータが何度もやり取りされるのは非効率です。そこで有効なのが「差分データ共有」です。最初の通信でベースとなるデータを共有した後は、変更があった部分(差分)だけを通知し合います。
例えば、在庫監視システムで、全商品の在庫リストを毎分共有するのではなく、「商品Aの在庫が1つ減少」「商品Bが再入荷」といったイベント(差分情報)のみを共有します。これにより、通信データ量を劇的に削減でき、結果としてLLMのAPIコストやネットワーク帯域の節約に繋がります。
高度なデータ共有戦略を成功させる鍵は「最小権限の原則」と「関心の分離」です。エージェントには自身のタスク遂行に必要最小限の情報と権限のみを与え、データ管理の責務を特定のコンポーネント(Orchestratorやデータ抽象化レイヤー)に集中させることが、堅牢なシステム設計に繋がります。
Claude Codeで実現する次世代のデータ共有基盤
ここまで解説してきたデータ共有アーキテクチャや戦略は、理論上は強力ですが、ゼロから実装するには相応の知識と工数が必要です。特に、セキュアな通信、エラーハンドリング、状態管理などを考慮すると、その複雑さは増すばかりです。
ここで注目したいのが、マルチエージェント開発に特化したフレームワークの活用です。例えば「Claude Code」のようなツールは、マルチエージェントシステムの構築を強力にサポートする機能を備えています。
H3: サブエージェント間のセキュアな通信チャネル
フレームワークは、エージェント間の通信を抽象化し、開発者が煩雑なネットワークプログラミングを意識することなく、安全なデータ交換を実現できる仕組みを提供します。エージェント間通信機能により、複数のAIエージェントが連携してタスクを実行するシステムを、具体的な実装例を通して構築できます。
H3: Orchestrator実装を加速するテンプレートとツール
複雑になりがちなOrchestratorパターンの実装を支援するテンプレートやライブラリが用意されている場合が多くあります。これにより、開発者はビジネスロジックの実装に集中でき、PoCで終わらず、複数のAIエージェントが連携する本格的なシステム開発を実現し、業務効率化を推進できます。
H3: 運用を見据えたエラーリカバリと監視
データ共有のプロセスでエラーが発生した場合、それを検知し、適切に処理をロールバックしたり、リトライしたりする仕組みは不可欠です。高度なフレームワークには、こうしたエラーリカバリ機能が組み込まれており、AIシステムの運用におけるエラー発生時の対応体制を確立し、本番環境での運用に対する不安を解消します。
マルチエージェントシステムの開発では、最初から完璧で複雑なデータ共有基盤を目指す必要はありません。まずはシンプルなOrchestratorパターンから始め、システムの成長に合わせて共有データストアやPub/Subパターンを組み込むなど、段階的にアーキテクチャを進化させていくアプローチが成功の鍵です。
まとめ
本記事では、マルチエージェントシステムにおけるデータ共有という、重要かつ複雑なテーマについて掘り下げてきました。最後に、この記事の重要なポイントを振り返りましょう。
- マルチエージェントのデータ共有には「セキュリティ」「効率性」「整合性」という3つの大きな課題が存在する。
- 課題解決の基本となるアーキテクチャには「Orchestratorパターン」「共有データストアパターン」「Pub/Subパターン」があり、要件に応じて選択・組み合わせる。
- より堅牢なシステムを構築するためには、RBAC、データ抽象化、差分共有といった高度な戦略が有効である。
- 開発フレームワークを活用することで、これらの複雑なアーキテクチャの実装コストを大幅に削減し、本番運用に耐えうるシステムを効率的に構築できる。
理論やパターンを学ぶことは非常に重要ですが、真の理解は実践を通じて得られます。あなたが今、マルチエージェントシステムの設計や実装で悩んでいるのであれば、次のステップとして、これらのアーキテクチャが実際にどのようにコードに落とし込まれるのかを学ぶことをお勧めします。
より詳細な実装方法や、本記事で紹介したコンセプトを深く学びたい方には、『Claude Codeマルチエージェント開発 -- 設計・実装・運用の実践ガイド』が最適です。この書籍では、Claude Codeのサブエージェント機能を使い、複数のAIエージェントが協調して動くシステムの設計から実装、そして運用に至るまで、具体的なコード例を交えながら網羅的に解説しています。データ共有アーキテクチャはもちろん、エラーリカバリやコスト最適化など、本番運用に欠かせない実践的なノウハウが満載です。ぜひ、あなたのAI開発を次のレベルへと引き上げるためにご活用ください。